
Monitoring and Logging Strategies for API Gateways: Essential for Modern Application Health
Many teams treat monitoring and logging as reactive measures, but the truth is they need to be baked in from the start.

Introduction
API gateways are not just add ons in distributed systems but the foundation of modern application operational efficiency. When you have microservices, the API gateway is the glue that holds everything together and ensures data flow and service coordination. While we all acknowledge its role, we often underestimate the depth of strategy required to run a good gateway. Many teams treat monitoring and logging as reactive measures, but the truth is they need to be baked in from the start.
Monitoring
To see why, think about all the metrics an API gateway needs to track. We can easily fall into the trap of just monitoring uptime and error rates but that’s just scratching the surface of system health. Comprehensive monitoring is not just about response times and request volumes but also the interaction dynamics of all the services involved, including authentication layers, databases and 3rd party APIs. Ignoring this holistic view is like driving blindfolded: issues remain hidden until they become critical failures. Monitoring must provide a full spectrum of visibility, capturing granular data on service dependencies and real time performance.
Logging
Logging is just as important. Inadequate or inconsistent logging leaves big blind spots during incident resolution. Logging every request and response is a given, but effective logging goes further, it’s about structured, queryable data. It’s not about capturing the events, it’s about making sure those logs can be analyzed to trace errors, find patterns and root causes. Without structured logging, debugging is an exercise in frustration where important information is buried under noise. Centralized logging systems like ELK Stack or Fluentd are particularly useful in aggregating logs across microservices and giving you a single view of system behavior.
Performance Monitoring
Performance monitoring is another area that needs attention. An API gateway under load can become a bottleneck and introduce latency that propagates throughout the application. Real time dashboards, customized to show gateway throughput and latency trends, allow teams to detect and fix performance degradation before it hits the end user. Tracing tools like Jaeger and Zipkin give you a 360 degree view of the request flow from the gateway to the backend services, where you can see where the delays or errors occur. Tracing is particularly useful in microservice architecture where without a clear request lineage it can be a manual detective work to find the issues.
Security
The importance of security cannot be overstated. API gateways are prime targets for attacks, given their role as the entry point for all client requests. Logging and monitoring, when applied correctly, provide a defense mechanism by identifying anomalies in access patterns, flagging failed authentication attempts, and tracking suspicious IP activities. Intrusion detection systems and real-time threat analysis tools amplify this capability, enabling teams to respond swiftly to potential breaches. Security monitoring must be continuous, integrated deeply into the overall strategy, and capable of scaling as threats evolve.
Scalability
Speaking of scalability, the ability to adapt monitoring and logging infrastructure to handle increased traffic and complexity is a non-negotiable requirement. As service demands grow, so does the data generated by monitoring tools. Systems must be designed to scale horizontally, ensuring no gaps emerge in data collection or alerting. It's not just about adding more resources but optimizing the architecture to handle higher throughput without sacrificing performance or accuracy. Auto-scaling features for monitoring and logging tools, coupled with cloud-native deployment practices, ensure that the infrastructure remains resilient and capable under any load.
Conclusion
Effective monitoring and logging strategies require a mindset shift. They are not afterthoughts or auxiliary processes but integral components of a resilient system. By prioritizing these strategies, teams gain the ability to preempt failures, maintain high performance, and secure their applications against evolving threats. The value lies in the visibility they provide, offering actionable insights that enhance system reliability and operational efficiency. To overlook them is to invite unnecessary risk and complexity, but with a well-executed approach, these strategies become the foundation of a robust and enduring architecture.
Share this article
Related Articles
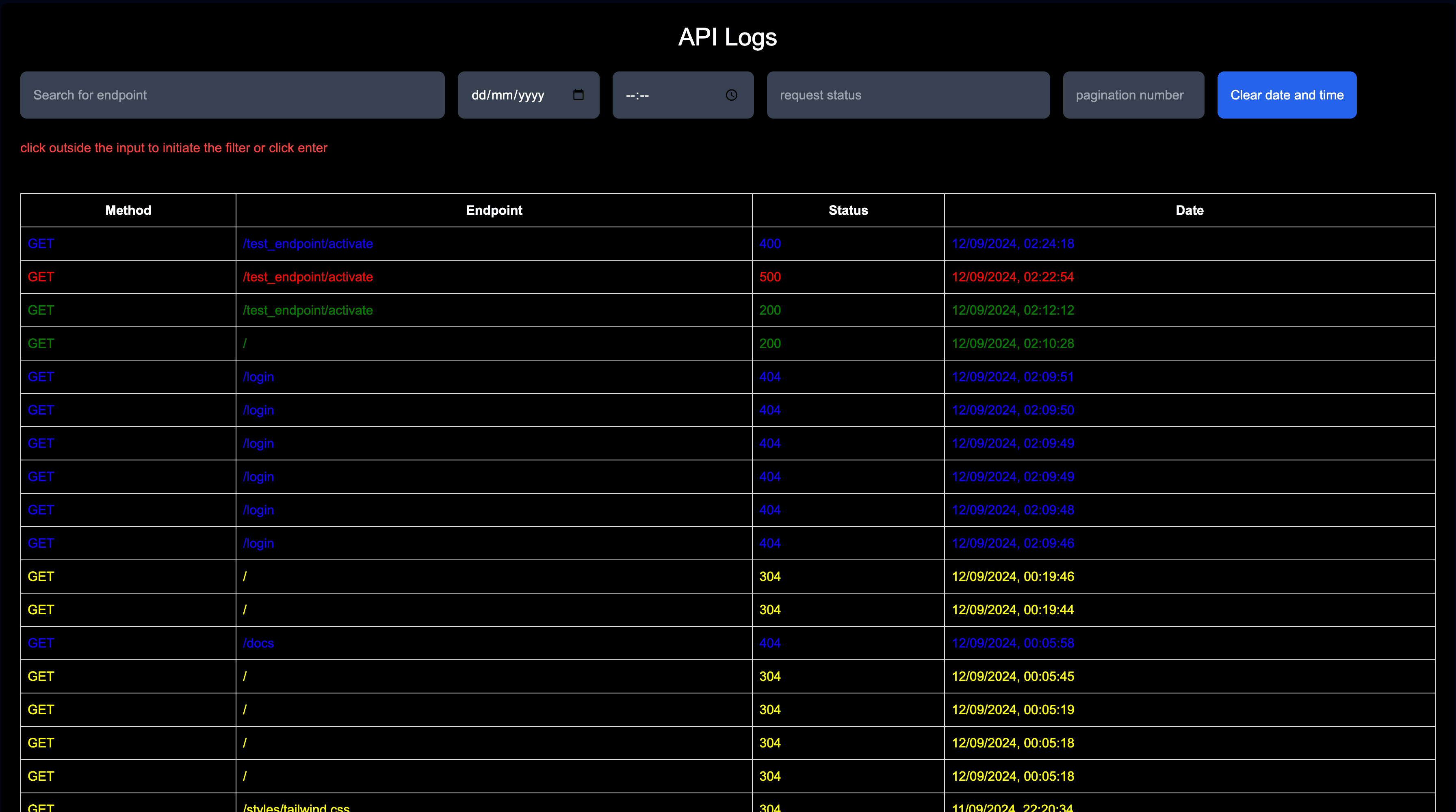
Node.js API Monitor: How to Track API Logs for Free
Learn how to monitor API logs in Node.js for free. Store and search requests easily, with additional features to enhance your API monitoring.
Ugochukwu Paul
7 months ago

IMPLEMENTING OBSERVABILITY IN DISTRIBUTED CLOUD SYSTEMS
The implementation of observability in distributed cloud systems is a foundational necessity for ensuring system reliability and operational effectiveness.
Chinedu Otutu
10 months ago

Understanding Swap Files in Linux: How to Use Disk Storage as Additional RAM
Learn how to use your disk storage as additional RAM in linux.
Ugochukwu Paul
6 months ago